
صار موضوع الذكاء الاصطناعي الشغل الشاغل للنخبة في عالم التكنولوجيا منذ أن أطلقت شركة أوپن إيه آي برنامجها للدردشة الآلية تشات جي پي تي في نوفمبر/تشرين الثاني 2022. راسلني وأنا أكتب هذه المقالة مؤسس إحدى شركات التكنولوجيا في لندن ليخبرني بأن هذا النوع من الذكاء الاصطناعي هو "كل ما أفكر فيه هذه الأيام"، وقال إنه بصدد إعادة تصميم شركته، التي تقدر قيمتها بمئات الملايين من الدولارات، حول نماذج اللغة الكبيرة، وهو ليس وحيدًا في ذلك.
يجسد تشات جي پي تي معرفة أكثر مما من قدرة أي إنسان على الاطلاع. يمكنه التحدث بشكل مقنع عن استخراج المعادن في پاپوا غينيا الجديدة، أو حول شركة تايوانية لأشباه الموصلات تجد نفسها في تقاطع جيوسياسي. لقد نجح جي پي تي 4 في الاختبارات التي تعد بمثابة بوابات للناس لدخول وظائف في القانون والطب في أميركا. يمكنه أن يولد الأغاني والقصائد والمقالات، وصار بإمكان نماذج "الذكاء الاصطناعي التوليدية" الأخرى إنتاج الصور الرقمية والرسومات والرسوم المتحركة.
يوجد قلق عميق مصاحب للإثارة في داخل صناعة التكنولوجيا وفي خارجها، حيث تسارعت وتيرة تطوير نماذج الذكاء الاصطناعي التوليدية للغاية. جي پي تي 4 نوع من الذكاء الاصطناعي التوليدي يسمى نموذج اللغة الكبير (LLM). قام عمالقة التكنولوجيا مثل ألفاپت وأمازون ونيڨيديا بتدريب نماذج اللغة الكبيرة لديهم، ومنحوها أسماء مثل PaLM وMegatron وTitan وChinchilla.
تعاظم الإغراء
يقوس مؤسس الشركة التكنولوجية في لندن إنه "قلق بشكل لا يصدق من التهديد الوجودي" الذي يشكله الذكاء الاصطناعي، حتى وهو يعمل به وعليه، وهو كذلك "يتحدث مع مؤسسين [آخرين] حول هذا الموضوع يوميًا". بدأت الحكومات في أميركا وأوروبا والصين في التفكير في وضع لوائح جديدة. تدعو أصوات البارزة إلى إيقاف تطوير الذكاء الاصطناعي مؤقتًا، خشية أن يخرج البرنامج عن السيطرة بطريقة ما ويضر بالمجتمع البشري، أو حتى يدمره. لتعرف حجم القلق أو الحماسة المطلوبين من هذه التكنولوجيا، علينا أولًا أن نفهم أصولها، وكيف تعمل، وحدود نموها.
بدأ الانفجار المعاصر لقدرات برمجيات الذكاء الاصطناعي في أوائل عام 2010، عندما أصبحت تقنية برمجية تسمى "التعلم العميق Deep Learning"[1] شائعة. أدى التعلم العميق، باستخدام المزيج السحري من مجموعات البيانات الضخمة وأجهزة الكمبيوتر القوية التي تشغل الشبكات العصبية على وحدات معالجة الرسومات GPU، إلى تحسين قدرات أجهزة الكمبيوتر بشكل كبير في التعرف على الصور ومعالجة الصوت وتشغيل الألعاب. تمكنت أجهزة الكمبيوتر بحلول أواخر عام 2010 من القيام بالعديد من هذه المهام بشكل أفضل من أي إنسان.
تميل الشبكات العصبية إلى أن تكون مضمنة في برامج ذات وظائف أوسع، مثل البريد الإلكتروني، ونادرًا ما تفاعل غير المبرمجين مع أنظمة الذكاء الاصطناعي هذه بشكل مباشر، أما أولئك الذين تفاعلوا معها وصفوا تجربتهم في كثير من الأحيان بعبارات شبه روحية. تقاعد لي سيدول أحد أفضل اللاعبين في العالم في لعبة الغُو Go، وهي لعبة لوحية صينية قديمة، من اللعبة بعد أن سحقه برنامج ألفاغو AlphaGo القائم على الشبكة العصبية لشركة ألفاپت في عام 2016، وقال: "حتى لو كنت الأفضل، فسيبقى هناك خصمٌ لا يمكن هزيمته".
يتيح تشات جي پي تي الآن، من تفاعله عبر وسيط المحادثة، للجمهور الذي يستخدم الإنترنت تجربة شيء مشابه، تجربة دوار فكريٍ من البرامج التي تحسنت فجأة لدرجة أنه يمكنها أداء المهام التي كانت حصرية طوال الفترة الماضية لمجال الذكاء البشري. وعلى الرغم من هذه الإثارة السحرية للذكاء الاصطناعي، فإن نماذج اللغة الكبيرة تعمل بناءً على النماذج الإحصائية. اطلب من تشات جي پي تي إنهاء الجملة: "تعدنا نماذج اللغة الكبيرة بـ... The promise of large language models is that they…" وستحصل على استجابة فورية، فكيف يعمل هذا النموذج؟
أولًا، يتم تحويل لغة الطلب/الأمر من الكلمات، التي لا تستطيع الشبكات العصبية معالجتها، إلى مجموعة تمثيلية من الأرقام (انظر الشكل رقم 1). يعمل جي پي تي 3 على تقسيم النص إلى أجزاء من الأحرف، تسمى الرموز المميزة، والتي تحدث عادةً معًا. يمكن أن تكون هذه الرموز عبارة عن كلمات، مثل "love" أو "are"، أو الإضافات، مثل "dis" أو "ised"، أو علامات الترقيم، مثل "؟". يحتوي قاموس جي پي تي 3 على تفاصيل 50257 رمزًا مميزًا.

الترميز
جي پي تي 3 قادر على معالجة 2048 رمزًا كحد أقصى في المرة الواحدة، وهو ما يقارب طول مقال طويل موقع ذا إيكونوميست. ويمكن لجي پي تي 4 التعامل مع مدخلات تصل إلى 32000 رمز طويل (بطول رواية قصيرة). كلما زاد طول النص الذي يمكن للنموذج أن يستوعبه، زاد السياق الذي يمكنه رؤيته، وكانت إجاباته أفضل. يرتفع الحساب المطلوب بشكل غير خطي مع طول المدخلات، مما يعني أن المدخلات الأطول قليلًا تحتاج إلى قوة حوسبة أكبر بكثير. ويجري بعد ذلك تعيين الرموز المكافئة للتعريفات من خلال وضعها في "مساحة المعنى" حيث توجد الكلمات التي لها معاني متشابهة في مناطق مجاورة.
التضمين

تعمل نماذج اللغة الكبيرة بعدها على نشر "شبكة الانتباه" الخاصة بها لإجراء اتصالات بين أجزاء مختلفة من الطلب/الأمر. إذا ما قرأ شخص ما طلبنا "تعد نماذج اللغة الكبيرة بـ..."، سيعرف قواعد اللغة الإنجليزية وسيفهم المفاهيم الكامنة وراء الكلمات في الجملة، وستكون العلاقة بين الكلمات واضحة له، مثل أن صفة الكبير تعود على النموذج. أما نماذج اللغة الكبيرة فتتعلم هذه العلاقات من الصفر خلال مرحلة التدريب، وعلى مليارات البيانات. تعمل "شبكة الانتباه" في تلك النماذج على تركيز اللغة التي تراها كأرقام (تسمى "أوزان") داخل شبكتها العصبية. تفهم نماذج اللغة الكبيرة اللغات البشرية بوصفها إحصاءات، ولا تفهمها نحويًا. وهي بذلك تشبه معدادًا أكثر من كونها عقلًا.
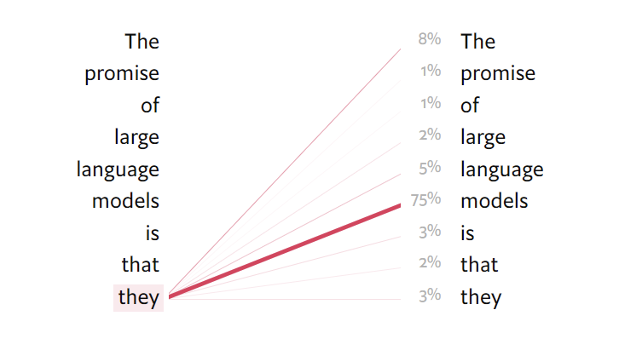
يبدأ النموذج بالاستجابة بمجرد معالجة الطلب. تنتج شبكة الانتباه في هذه المرحلة لكل من الرموز المميزة في مفردات النموذج احتمالية أن يكون هذا الرمز هو الأكثر ملاءمة لاستخدامه بعد ذلك في الجملة التي يتم إنشاؤها. الرمز المميز ذو أعلى درجة احتمالية ليس دائمًا هو الرمز الذي يتم اختياره للاستجابة، تعتمد عملية الاختيار على مدى الإبداع الذي وضعه خالقو النموذج فيه.

تقوم نماذج اللغة الكبيرة بإنشاء كلمة ثم تعيد النتيجة إلى نفسها. يتم إنشاء الكلمة الأولى بناءً على الطلب وحده. يتم إنشاء الكلمة الثانية من خلال تضمين الكلمة الأولى في الاستجابة، ثم الكلمة الثالثة بتضمين أول كلمتين تم إنشاؤهما، وهكذا. تتكرر هذه العملية، والتي تسمى الانحدار التلقائي، حتى انتهاء النموذج من الاستجابة.
الإكمال
لا يمكن التنبؤ بمخرجات نماذج اللغة الكبيرة على الرغم من إمكانية وضع قوانين خاصة كليفية عملها. واتضح لنا أن هذه المعدادات الكبيرة للغاية يمكنها القيام بمهام لا تستطيع نماذج اللغة الصغيرة القيام بها، حتى بطرق تفاجئ الأشخاص الذين يصنعونها. قام جيسون وي، الباحث في أوبن إيه آي، بإحصاء 137 قدرة "ناشئة" عبر مجموعة متنوعة من نماذج اللغة الكبيرة المختلفة.
القدرات "الناشئة" ليست سحرية، حيث تظهر جميعًا بشكل ما في بيانات التدريب (أو بناءً على شكل الطلب/الأمر المقدّم) ولكنها لا تصبح واضحة إلا بعد أن تتجاوز النماذج عتبة معينة كبيرة جدًا في حجمها. مثلًا، قد لا يعرف النموذج بحجم معين كيفية كتابة جملة شاملة للجنسين باللغة الألمانية على الإطلاق، ولكن لو جعلنا النموذج أكبر قليلًا، فستنبثق لديه قدرة جديدة. اجتاز جي پي تي 4 امتحان المحامين الأميركي الموحد المصمم لاختبار مهارات المحامين قبل أن يصبحوا مرخصين، بدرجة ممتازة (في التسعينات). فشل جي پي تي 3.5 في هذا الاختبار.

القدرات الناشئة مثيرة لأنها تنبهنا إلى الإمكانات غير المستغلة لنماذج اللغة الكبيرة. أظهر جوناس ديگريف، المهندس في شركة ديپ مايند DeepMind، وهي شركة أبحاث للذكاء الاصطناعي مملوكة لشركة ألفاپت، أنه يمكن إقناع تشات جي پي تي بالعمل مثل واجهة الأوامر السطرية، حيث يبدو أنه يجمع البرامج ويشغلها بدقة. ولو تطورت النماذج قليلًا، ستكون قادرة على تنفيذ طيف واسعٍ من الأمور الجديدة المفيدة، وهو ما يبعث على القلق لدى الخبراء، إذ تظهر التحليلات مثلًا أن بعض التحيزات الاجتماعية تظهر عندما تصبح النماذج كبيرة. ليس من السهل تحديد السلوكيات الضارة التي قد تكون كامنة، والتي تظهر مع زيادة حجم النموذج.
معالجة البيانات
يرجع النجاح الأخير الذي حققته نماذج اللغة الكبيرة في إنشاء نص مقنع، فضلًا عن قدراتها الناشئة المذهلة، إلى اندماج ثلاثة أشياء: تجميع كميات هائلة من البيانات، وخوارزميات قادرة على التعلم منها، والقدرة الحسابية للقيام بذلك (انظر شكل رقم 6). لم يتم الإعلان عن تفاصيل إنشاء ووظيفة جي پي تي 4 بعد، ولكن تم نشر تفاصيل جي پي تي 3 في ورقة بعنوان "Language Models are Few-Shot Learners"، نشرتها أوپن إيه آي في عام 2020.
تكون الأوزان في الشبكة العصبية لـ جي پي تي 3 في الغالب عشوائية قبل أن يرى أي بيانات تدريبية، ومن ثمّ فإن أي نص سينتجه البرنامج قبل التدريب سيكون عديم المعنى. يكمن سبب تفوق هذا البرنامج والتطبيقات الأخرى وقدرتها على كتابة النصوص في التدريب. تدرب جي پي تي 3 على مصادر بيانات عدّة، ولكن الجزء الأكبر من تدريبه يأتي من لقطات أخذها من كامل الشبكة العنكبوتية بين عامي 2016 و2019 من قاعدة بيانات تسمى Common Crawl. توجد الكثير من النصوص العشوائية عديمة القيمة على الإنترنت، ولذلك صُفيَّت الـ 45 تيرابايت الأولية باستخدام نموذج مختلف للتعلم الآلي لاختيار النوص عالية الجودة فقط: 570 غيغابايت منها، وهي مجموعة بيانات يمكن أن تملأ قرص تخزين لكومبيوتر حديث. دُرب جي پي تي 4 على قدرٍ غير معروف من الصور والبيانات، ربما بالتيرابايت. تدرب أليكسا نت AlexaNet، شبكة عصبية لمعالجة الصور، على مجموعة بيانات تتكون من 1.2 مليون صورة مُصنّفة، أي ما مجموعه 126 غيغابايت، أقل من عُشر البيانات التي من المحتمل أن يكون جي پي تي 4 قد تدرب عليها.

تختبر نماذج اللغة الكبيرة نفسها، لأغراض التدريب، بناءً على النص المُعطى لها. حيث تأخذ جزءًا من الكلام، وتغطي بعض الكلمات منه، وتحاول تخمين باقي الكلمات. وعند تقديم الإجابة للسؤال أو الطلب أو الأمر، تُقارن بين الإجابة المُعطاة، وبين تخمينها. ونظرًا لوجود الإجابات في البيانات نفسها، يمكن تدريب هذه النماذج بطريقة "الإشراف الذاتي" على مجموعات البيانات الضخمة دون الحاجة إلى وجود مُصنِّفين بشريين.
يهدف هذا النموذج لتحسين تخميناته قدر الإمكان من خلال ارتكاب أقل عدد ممكن من الأخطاء، ولا تكون كل الأخطاء سواء. إذا كان النص الأصلي هو "I love ice cream"، فإن التخمين "I love ice hockey" أفضل من "I love ice are". يحوّل مدى سوء التخمين إلى رقمٍ ويسمى "الخسارة". بعد تقديم عددٍ من التخمينات، تُرسل "الخسارة" مرة أخرى إلى الشبكة العصبية ويجري استخدامها لدفع الأوزان في اتجاه ينتج عنه إجابات أفضل.
تقديّم الدَّهشة
تعد شبكات الانتباه في نماذج اللغة الكبيرة مفتاح التعلم من الكميات الهائلة من البيانات، فهي يبني في النموذج طريقة للتعلم واستخدام الارتباطات بين الكلمات والمفاهيم، حتى لو كانت متباعدة عن بعضها في النص، كما تسمح للنموذج بمعالجة رزم البيانات خلال فترة زمنية معقولة. تعمل العديد من شبكات الانتباه المختلفة بالتوازي داخل نماذج اللغة الكبيرة ويسمح هذا التوازي بتشغيل العملية عبر وحدات معالجة رسومات متعددة. لم تكن الإصدارات القديمة، التي لا تعتمد على شبكات الانتباه، من نماذج اللغة قادرة على معالجة مثل هذه الكمية من البيانات في فترة زمنية معقولة. يقول يوشوا بنجيو، المدير العلمي لمعهد بحوث الذكاء الاصطناعي البارز في كيبيك، ميلا: "بدون شبكات الانتباه، لن يكون ممكنًا قياس وحساب البيانات".
أدى النطاق الهائل من البيانات التي يمكن معالجتها في نماذج اللغة الكبيرة إلى نموها مؤخرًا. يتكون جي پي تي 3 من مئات الطبقات ومليارات الأوزان، وقد دُرِّب على مئات المليارات من الكلمات.

لكن هناك أسبابًا وجيهة للاعتقاد بأن هذا النمو لا يمكن أن يستمر إلى ما لا نهاية، كما يقول الدكتور بنجيو. فمدخلات نماذج اللغة الكبيرة تُكلّف الكثير من المال في التدريب على البيانات وشراء قوة الحوسبة وتوظيف العمالة الماهرة. على سبيل المثال، استخدم جي پي تي 3 في أثناء تدريبه 1.3 جيجاواط/الساعة من الكهرباء (ما يكفي لتشغيل 121 منزلًا في أميركا لمدة عام)، وكلف أوپن إيه آي ما يقدر بنحو 4.6 مليون دولار. جي پي تي 4 أطبر بكثير، ومن المرجع أنه كلّف الشركة حوالي 100 مليون دولار في مرحلة التدريب. ونظرًا لأن متطلبات طاقة الحوسبة تزداد بشكل أسرع من بيانات الإدخال، فإن تدريب نماذج اللغة الكبيرة يصبح مكلفًا بشكل أسرع مما يتحسن. في الواقع، يبدو أن سام التمان، رئيس شركة أوپن إيه آي، يعتقد أننا وصلنا إلى نقطة انعطاف تاريخي، إذ قال في 13 أبريل لجمهوره في معهد ماساتشوستس للتكنولوجيا: "أعتقد أننا وصلنا نهاية عصر نماذج اللغة الكبيرة والعملاقة، وسيتوجب علينا جعلها أفضل بطرقٍ أخرى".
يبقى أهم وأبرز حد للتحسين المستمر لنماذج اللغة الكبيرة هو مقدار بيانات التدريب المتاحة. دُرّب جي پي تي 3 بالفعل على كل نص ذي معنى وقيمة على الإنترنت. خلصت ورقة بحثية نُشرت في أكتوبر 2022 إلى أن "مخزون البيانات اللغوية عالية الجودة سينفد قريبًا، على الأرجح قبل عام 2026". من المؤكد المزيد من النصوص المتاحة، لكنها محجوزة بكميات صغيرة في قواعد بيانات الشركات أو على الأجهزة الشخصية، ولا يمكن الوصول إليها على نطاق واسع وبتكلفة منخفضة كما تسمح به Common Crawl.
ستصبح أجهزة الكمبيوتر أكثر قوة بمرور الوقت، ولكن لن تقدّم أي أجهزة جديدة قفزة كبيرة في الأداء مثل تلك التي جاءت من استخدام وحدات معالجة الرسومات في أوائل عام 2010، ولذلك من المحتمل أن يكون تدريب النماذج الأكبر مكلفًا بشكل متزايد، ولعل السيد ألتمان لن يكون متحمسًا لهذه الفكرة. التحسينات ممكنة، بما في ذلك اختراع أنواع جديدة من الرقائق مثل وحدة معالجة Tensor من Google، لكن تصنيع الرقائق لم يعد يتحسن بشكل كبير بسبب قانون مور[2] ونظرية أن صناعة أشباه المواصلات ستعاني إذ لم تستمر الرقائق بالتطور والنمو بقفزات أسية كل عامين.
كم ستضرب القضايا القانونية سوق الذكاء الاصطناعي. رُفعت دعوى قضائية ضد شركة ستابيلتي إيه آي Stability AI، وهي شركة تملك نموذج ذكاء اصطناعي توليدي يسمى ستيبل ديفوجن Stable Diffusion، من شركة صُور گيتي Getty Images. تأتي بيانات تدريب تطبيق ستيبل ديفوجن من نفس المكان مثل جي پي تي 3 وجي پي تي 4 وموقع Common Crawl، وتعالج بياناتها بطرق مشابهة جدًا باستخدام شبكات الانتباه. قدّم الذكاء الاصطناعي أفضل أمثلته التوليدية في الصور. ينشغل الناس على الإنترنت الآن دوريًا بشأن الصور الظاهرة والمنتشرة لمشَاهدٍ لم تحدث، مثل صورة البابا مرتديًا سترة من ماركة بالينسياغا Balenciaga أو لصور اعتقال دونالد ترامب.
أشار موقع گيتي أن الصور التي ينتجها ستيبل ديفوجن تحتوي على العلامة المائية لحقوق النشر الخاصة بها، مما يشير إلى أن الشركة تبتلع وتعيد إنتاج مواد محمية بحقوق الطبع والنشر دون إذن (لم تعلق شركة ستابيلتي إيه آي على الدعوى حتى الآن). يصعب الحصول على نفس المستوى من الأدلة عند فحص مخرجات تشات جي پي تي النصية، ولكن لا يوجد شك أن البرنامج قد تدرب على مواد محمية. تأمل شركة أوپن إيه آي في أن تكون مخرجاتها برنامجها محمية بقانون "الاستخدام العادل"، وهو بند في قانون حقوق النشر يسمح بالاستخدام المحدود للمواد المحمية بحقوق الطبع والنشر في الأغراض "التحويلية"، ومن المحتمل أن يتم اختبار هذه الفكرة يومًا ما في المحكمة.
أداة رئيسة
ستظل قوة النماذج اللغوية الكبيرة قائمة، حتى لو توقف تطويرها هذا العام، وحتى لو دفعت شركة أوپن إيه آي أموالًا حد الإفلاس في المحاكم. البيانات والأدوات اللازمة لمعالجتها متاحة على نطاق واسع، حتى لو ظل النطاق الهائل الذي حققته الشركة باهظ التكلفة.
ومع تدريب التطبيقات مفتوحة المصدر بعناية وانتقائية، فإنها تقترب بالفعل من أداء جي پي تي 4، وهذا أمر جيد، ويعني أن قوة النماذج اللغوية الكبيرة صارت في أيدٍ عديدة، ما يعني ابتكار تطبيقات جديدة ومبتكرة تساهم في تحسين كافة المجالات من الطلب إلى القانون. ويعني أيضًا أن الأخطار التي تخيف النخبة التكنولوجية قد بدأت تصير واقعًا. تعد النماذج اللغوية الكبيرة قوية في وقتنا الحالي بشكل لا يصدق، وقد تحسنت بسرعة كبيرة لدرجة أن العديد من العاملين عليها قد أصيبوا بالفزع. لقد تجاوزت قدرات أكبر النماذج فهم وتحكم خالقيها، وهذا يعني أننا سنواجه أخطارًا من جميع الأنواع.
إحالات:
[1] وسيلة في حقل الذكاء الاصطناعي تقوم على تعليم أجهزة الكومبيوتر معالجة البيانات بطريقة مستوحاة من طريقة عمل الدماغ البشري، وتتعرف نماذج التعلم العميق على الصور والنصوص والأصوات والبيانات المعقدة الأخرى وتحولها لأرقام، وتقوم بإنتاج تنبؤاتها بناءً على المواد التي تدربت عليها.
[2] القانون الذي ابتكره غوردون مور أحد مؤسسي إنتل عام 1965، حيث لاحظ أن عدد الترانزستورات على شريحة المعالج يتضاعف تقريبا كل عامين في حين يبقى سعر الشريحة على حاله، وأدت هذه الملاحظة إلى بدأ عملية دمج السيليكون بالدوائر المتكاملة على يد شركة إنتل مما ساهم في تنشيط الثورة التكنولوجية في شتى أنحاء العالم، وفي عام 2005، تنبأ الباحثون أن هذه النظرية من الممكن تطبيقها لعقد آخر من الزمان على الأقل.
التعليقات